Дорожный пирог в разрезе с размерамиСтроительство дорожного пирога (Что такое? И для чего?)

Строительство дорог относится к дорогостоящим и трудоемким процессам. Да и состав дороги не ограничивается исключительно видимыми над поверхностью бордюрами и покрытием. Дорога является многослойным пирогом, предназначенным для выполнения важной задачи по перераспределению нагрузок на основание грунта. Для того, чтобы оптимизировать состав и строительство дорожного пирога, необходимо приобретение высококачественных геосинтетиков по экономичной стоимости в компании GeoSM, занимающейся производством всего ассортимента материалов и их оптовыми продажами.
Для производства наших материалов для дорожных работ мы разработали уникальную, запатентованную технологию. Мы много лет специализируемся на изготовлении высококачественных и уникальных геосинтетиков Геофлакс.
Рекомендуемые материалы:
Мы гарантируем, что все материалы соответствуют технологии создания дорожного пирога национальным стандартам и требованиям, предъявляемым регулирующими организациями.
Что такое дорожный пирог и для чего он служит?
Залогом надежной дороги является создание качественного дорожного пирога под асфальт. Благодаря многослойному основанию, состоящему из грунта, песка и щебня, и достигается длительность эксплуатации дорожного покрытия. Толщину слоя песка и щебня рассчитывают в соответствии с предполагаемыми нагрузками. Повышения качества пирога достигают благодаря трамбованию основания и смачиванию слоев.
Пирог дорожного покрытия служит для обеспечения безопасности движения и скоростного режима автотранспорта. Без дорожного пирога происходят преждевременные разрушения дорожного покрытия, что проявляется в образовании ямок и трещин.
Устройство дорожного пирога
 Пирог дорожного покрытия автомобильных дорог состоит из грунтового основания и подушки амортизации, которые разделяются с помощью геотекстиля, располагаемого в самом нижнем слое дорожной одежды. Геосинтетик служит для предотвращения смешивания грунта и амортизационных материалов, при этом не нарушая водного обмена грунта. Для основания дорог важно обеспечить дренирование дороги, чтобы предотвратить ее размытие.
Пирог дорожного покрытия автомобильных дорог состоит из грунтового основания и подушки амортизации, которые разделяются с помощью геотекстиля, располагаемого в самом нижнем слое дорожной одежды. Геосинтетик служит для предотвращения смешивания грунта и амортизационных материалов, при этом не нарушая водного обмена грунта. Для основания дорог важно обеспечить дренирование дороги, чтобы предотвратить ее размытие.
Пирог дорожного полотна делает неподвижной дорожную одежду. Благодаря исключению смешивания материалов обеспечивается стабильность дорожного покрытия и предотвращается образование разнообразных дефектов, от вспученного асфальта до глубоких ям.
Технология строительства дорожного пирога
Строительство начинается со снятия слоя грунта на трассе будущей дороги. После трамбовки и уплотнения грунта его покрывают геотекстилем. Затем укладывается подстилающий слой песка для амортизации и минимизации повреждений. Слои дорожного пирога состоят также из щебня различных фракций, укладываемого поверх песчаного слоя. Для закрепления щебня пользуются битумной эмульсией. Укладку асфальта осуществляют в несколько слоев.
Применение геосинтетических материалов для строительства дорожного пирога
Наряду с традиционно использующимися материалами (щебнем и песком) в программу технических заданий по устройству дорожного пирога включается применение геосинтетиков. Строители активно пользуются инновационными технологиями и ассортиментом качественных геосинтетических материалов, что обеспечивает заказчиков надежными покрытиями из асфальта или бетона, эстакадами и мостами. Благодаря повышению износоустойчивости пирога дорожной одежды достигают снижения стоимости обустройства дорог и периодичности осуществления ремонтов.
Геотекстиль Геофлакс для дорожного пирога
• 25%-ую экономию стройматериалов;
• устойчивость дорожного пирога;
• предотвращение плывучести;
• надежность связывания конструкции.
Применение геотекстиля наиболее эффективно в сочетании с геосеткой, что при перераспределении нагрузок служит созданию противоскользящего покрытия.
Геосетка Геофлакс для дорожного пирога
 Применение геосетки дает возможность для улучшения характеристик по эксплуатации и снижения затрат на строительство на 45%. Геосетка при эксплуатации показывает высокую устойчивость к процессу деформирования.
Применение геосетки дает возможность для улучшения характеристик по эксплуатации и снижения затрат на строительство на 45%. Геосетка при эксплуатации показывает высокую устойчивость к процессу деформирования.
В современной обстановке требуется стремиться к увеличению периода эксплуатации материалов, используемых при обустройстве дорожных покрытий. Нам отлично известно, что долговечность дорожного пирога зависит от соответствия всем запросам отрасли, проведения работ в соответствии с требованиями заказчиков, нормами существующих стандартов.
Оставить заявкуСкачать прайс
С материалами GeoSM добиваются существенного ускорения работ по устройству пирога дорожного покрытия. Применять геосинтетику GeoSM рекомендуют профессионалы.
Подписаться на рассылку Полезной информации можно через форму ниже:
Пирог дороги,срез дорожного полотна. Конструкция дороги.
Для начала нужно понять, как работает асфальтированная дорога, как и какие нагрузки, она воспринимает и распределяет.
Асфальт сам по себе, плохо работает на изгиб (скручивание, различные силы имеющие плечо), так как, структура асфальта гранулированная. В повседневной жизни это можно наблюдать в осенне-зимний, весенний период т.е. тогда когда влажный грунт замерзает. При замерзании почва расширяется на 10%, тем самым создавая выдавливающую силу на дорогу.
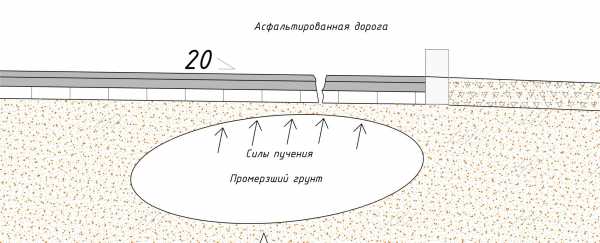
Железобетон к примеру с этой задачей справляется куда лучше за счет расположения металлических стержней в своём теле.
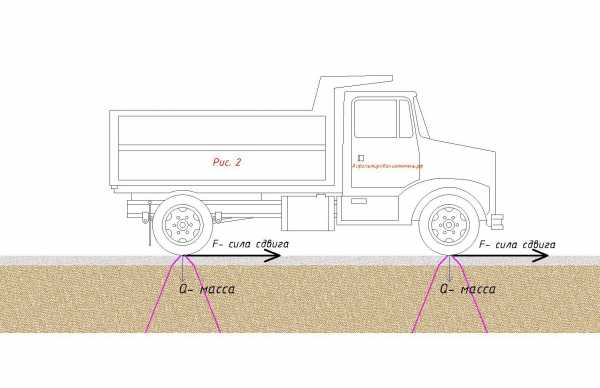
В то же время асфальт очень хорошо сопротивляется сдвигу и срезу, например при торможении автомобиля. Так как гранулы асфальта связаны между собой битумом.
Основная задача асфальтового полотна не только воспринимать нагрузки на сдвиг и срез, но и передавать вес транспортного средства с поверхности на нижележащие слои с расширяющимся полем восприятия нагрузки. Рис 2.
РАЗРЕЗ ДОРОГИ
Другими словами готовить дорожный разрез нужно весь полностью, от нижнего слоя к самому асфальту.
В противном случае полотно начнет ломаться, образовываться ямы и другие различные дефекты дорожного покрытия.
Принцип передачи нагрузки от автомобиля на дорожное покрытия
Математически выглядит это так: 1, м2 АБС должен передавать нагрузку на 1м2+X, основания где, X- больше ноля.
В физическом смысле тут нет ни чего сложного, все дело в том, что фракция основания(щебня) должна быть больше фракции наполнения АБС.
Например: фракция щебня в асфальте класса А, 5-20, 5-10 и меньше, а фракция щебня в основании, 20-40. Раз частицы щебня основания крупнее, то они увеличивают поле нагрузки передаваемое верхним слоем дорожного покрытия, от колес автотранспорта и других нагрузок. Ни в коем случае, не нужно, укладывать крупнозернистый асфальт на мелкозернистое основание!
Именно поэтому например на больших федеральных автострадах и автобанах, где высокая интенсивность и скорость движения, конструкция дорожного полотна имеет многослойную структуру. В последнее время стали активно применять различные стеклянные, базальтовые сетки, нетканое полотно, различные добавки в АБС, ЩМА итд.
Технологии современного асфальтирования развиваются год от года. Появляется масса нового материала и инновационные технологии укладки асфальта, которые улучшают характеристики дорожного покрытия.
Сейчас применение дорожной сетки и мембраны занимает 5-10% от затрат на материалы. В то же время позволяет значительно улучшить характеристики по нагрузке, интенсивности, прочности дороги, и значительно экономит материал.
Конструкция дороги в частных домах, около коттеджа, дачи, парковка
При работе с небольшими площадями, как правило используется упрощенная технология укладки асфальтового покрытия. На данных объектах не требуются высокие характеристики АБС. Для того что бы припарковать личный автомобиль у своего коттеджа, нет необходимости строить многослойную конструкцию корыта дороги.
Так же хотелось отметить тот факт что, для благоустройства небольших объемов, может используется виброплита.
Поле глубины уплотнения у виброплиты составляет от 15 см , что вполне достаточно для послойной трамбовки и укладки асфальта на не больших придомовых территориях.
Надеюсь в данной статье вы узнали полезную информацию по выбору конструкции “дорожного пирога” и немного прояснитли механику и принципы работы дорожного покрытия.
Так же вы можете задать свои вопросы тут, и мы ответим на них!
Пополните свои публикации значками измерений
Начиная с цифрового века, доступ к опубликованной литературе и исследованиям продолжал развиваться. Это означает, что у нас море изобильной информации, и люди все больше полагаются на показатели, чтобы помочь выявить тенденции и влияние. Предоставление данных доступными способами, которые являются наиболее полезными для исследовательского сообщества, продолжает оставаться ключевым приоритетом для команды Dimensions. Вместе с этой миссией мы также хотели предоставить простые методы для разблокировки этих данных и эффективной оценки исследовательской среды.
Чтобы создать больше контекста для богатых и взаимосвязанных данных и предложить дальнейшее исследование, мы создали значок измерений. Значки предоставляют в реальном времени и легко усваиваемый снимок истории цитирования публикации. Цитаты из собственного индекса цитирования Digital Science представлены в дополнение к трем другим показателям цитирования. Кроме того, значок показывает, откуда взялись цитаты, как они цитируются с течением времени, и какие категории исследований ссылаются на контент.

Каждая публикация в базе данных измерений сопровождается собственным уникальным значком. Первое, что вы видите на цветном значке, - это количество цитирований, но один клик открывает более полную страницу сведений с еще более полезной информацией, включая новые показатели эффективности цитирования, такие как коэффициент цитирования поля (FCR), коэффициент относительного цитирования (RCR). ) И визуализация, которая помогает пользователям понять, является ли количество ссылок, полученных публикацией, высоким, низким или средним по сравнению с другими публикациями в той же области.
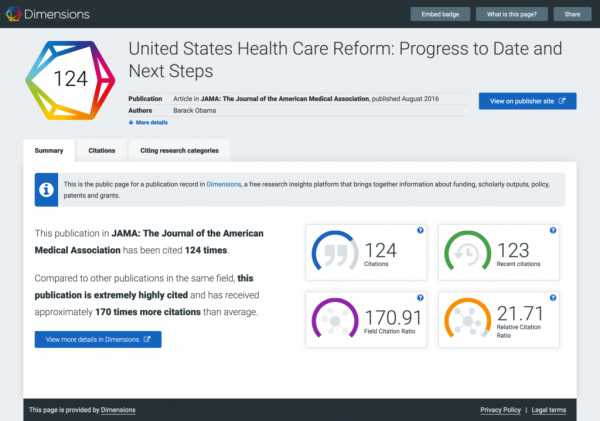
Более 250 издателей и платформ уже добавили значки измерений на свой веб-сайт, предоставляя немедленную информацию о влиянии статьи на данные о цитировании и альтметрию. Некоторые заслуживающие внимания партнеры, которые интегрировали значки Dimensions, - это IOP Science, ICE Publishing, Ingenta Connect, IntechOpen, PubFactory, ARPHA и многие другие.
Стюарт Такер, руководитель отдела цифровой доставки в IOP, сказал: «Улучшение информации о цитировании, доступной для читателей IOPscience, было нашей целью.Ранее читатели могли видеть только общее количество цитирований и список мест, где цитировалась статья. Значки Размеры предоставляют гораздо больше деталей и. Ввести их было легко.
Эти значки позволяют авторам, редакторам, рецензентам журнала и посетителям их сайта просматривать данные цитирования с помощью четкой интерактивной визуализации. Вкладка Citing Research Categories предоставляет пользователям визуализацию, которая иллюстрирует, сколько раз публикация цитировалась в различных областях исследований, как указано кодами Fields of Research (FoR).Это представляет собой новый способ визуализации влияния публикации на исследования, как внутри, так и между дисциплинами.
Мы позволяем издателям встраивать значки измерений в их сайт с помощью простой строки кода. Значки можно использовать бесплатно, если издатель имеет соглашение об индексировании с Digital Science. Вы также можете настроить внешний вид значка в соответствии с целевой страницей контента. Мы приглашаем издателей связаться с представителем вашей учетной записи Digital Science по вопросам индексации или нажмите здесь для получения дополнительной информации.
Понимание размеров в PyTorch | Боян Бараков
Однако, как я уже сказал, более важной проблемой было направление каждого измерения. Вот что я имею в виду. Когда мы описываем форму 2D-тензора, мы говорим, что он содержит около строк, и около столбцов. Итак, для тензора 2x3 у нас есть 2 строки и 3 столбца:
>> x = torch.tensor ([
[1, 2, 3],
[4, 5, 6]
]) >> x.shapetorch.Size ([2, 3])
Сначала мы указываем строки (2 строки), а затем столбцы (3 столбца), верно? Это привело меня к выводу, что первое измерение ( dim = 0 ) остается для строк, а второе ( dim = 1 ) для столбцов.Исходя из того, что размер dim = 0 означает построчное вычисление, я ожидал, что torch.sum (x, dim = 0) приведет к тензору 1x2 ( 1 + 2 +) 3 и 4 + 5 + 6 для результата тенге [6, 15] ). Но оказалось, что у меня есть что-то другое: тензор 1x3 .
>> torch.sum (x, dim = 0) тензор ([5, 7, 9])
Я был удивлен, увидев, что реальность была противоположна тому, что я ожидал, потому что я наконец получил результат тензор [6, 15] , но при передаче параметра дим = 1 :
>> факел.сумма (x, dim = 1) тензор ([6, 15])
Так почему же это так? Я обнаружил статью Aerin Kim, посвященную той же путанице, но для матриц NumPy, где мы передаем второй параметр, называемый axis . Сумма NumPy практически идентична той, что есть в PyTorch, за исключением того, что dim в PyTorch называется осью в NumPy:
numpy.sum (a, axis = None, dtype = None, out = None, keepdims = False )
Ключ к пониманию того, как dim в PyTorch и ось в NumPy работают в этом параграфе, в статье Aerin:
Способ понять, что такое « ось », - это коллапсов указанная ось.Таким образом, когда он сворачивает ось 0 (строка), он становится только одной строкой (суммируется по столбцам).
Она очень хорошо объясняет работу параметра по оси на numpy.sum. Однако становится сложнее, когда мы вводим третье измерение. Когда мы посмотрим на форму трехмерного тензора, мы заметим, что новое измерение предварительно соединено и занимает первую позицию (жирным шрифтом , ниже ), то есть третье измерение становится dim = 0 .
>> у = факел.тензор ([
[
[1, 2, 3],
[4, 5, 6]
],
[
[1, 2, 3],
[4, 5, 6]
],
[
] [1, 2, 3],
[4, 5, 6]
]
]) >> y.shapetorch.Size ([ 3 , 2, 3])
Да, это довольно запутанно. Вот почему я думаю, что некоторые основные визуализации процесса суммирования по различным измерениям будут в значительной степени способствовать лучшему пониманию.
Первое измерение ( dim = 0 ) этого трехмерного тензора является наибольшим и содержит 3 двумерных тензора.Таким образом, чтобы суммировать его, мы должны сложить его 3 элемента друг над другом: тензор
>> torch.sum (y, dim = 0) ([[3, 6, 9],
[12, 15, 18] ]])
Вот как это работает:
Для второго измерения ( dim = 1 ) мы должны свернуть строки:
>> torch.sum (y, dim = 1) тензор ([[5, 7, 9],
[5, 7, 9],
[5, 7, 9]])
И, наконец, третье измерение рушится над столбцами:
>> torch.sum (y, dim = 2 ) тензор ([[6, 15],
[6, 15],
[6, 15]])
Если вы похожи на меня, недавно начали изучать PyTorch или NumPy, надеюсь, эти базовые анимированные примеры помогут Вы получите лучшее понимание того, как работают измерения, не только для сумм , но и для других методов.
Спасибо за чтение!
Источники:
[1] А. Ким, Интуиция оси Numpy Sum
.от кластеров, PCA, t-SNE ... до Карла Сагана!
Игра с размерами
Привет! Этот пост является экспериментом, объединяющим результат t-SNE с двумя хорошо известными методами кластеризации: k-средних и иерархической . Это будет практический раздел, в R .
Кроме того, в этом посте будут рассмотрены точки пересечения таких понятий, как сокращение измерений, кластерный анализ, подготовка данных, PCA, HDBSCAN, k-NN, SOM, глубокое обучение...и Карл Саган!
PCA и т-SNE
Для тех, кто не знает методику t-SNE (официальный сайт), это метод проекции - или уменьшение размеров - в некоторых аспектах аналогичный анализу основных компонентов (PCA), который используется для визуализации N переменных в 2 (например, ).
Когда выход t-SNE плохой, Лорен ван дер Маатен (автор t-SNE) говорит:
Для проверки работоспособности попробуйте запустить PCA для ваших данных, чтобы уменьшить их до двух измерений. Если это также дает плохие результаты, то, возможно, в ваших данных не очень хорошая структура.Если PCA работает хорошо, а t-SNE - нет, я уверен, что вы сделали что-то не так.
По моему опыту, делая PCA с десятками переменных с:
- некоторые экстремальные значения
- перекошенных распределений
- несколько фиктивных переменных,
Не приводит к хорошим визуализациям.
Посмотрите на этот пример, сравнивая два метода:
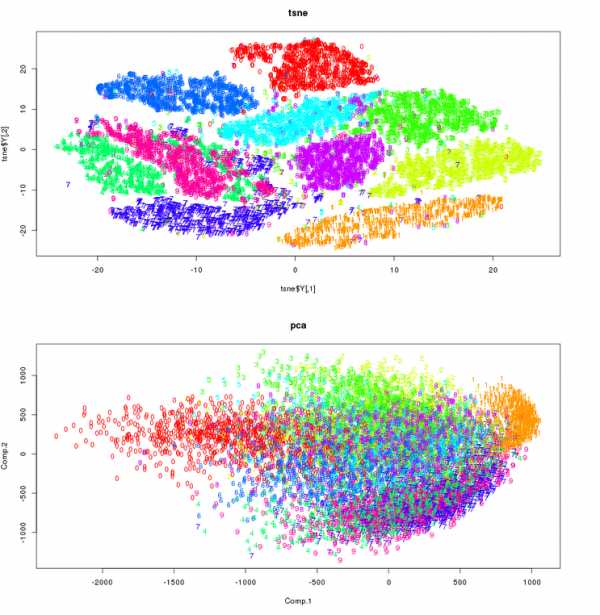
Источник: кластеризация в 2-х измерениях с использованием tsne
Имеет смысл, не так ли?
Серфинг больших размеров 🏄
Поскольку один из результатов t-SNE представляет собой матрицу двух измерений, где каждая точка представляет входной регистр, мы можем применить кластеризацию и затем сгруппировать наблюдения в соответствии с их расстоянием в этой двумерной карте .Как карта географии делает с отображением 3-х мерности (наш мир) на две (бумага).
t-SNE объединяет похожие случаи, очень хорошо обрабатывая нелинейности данных. После использования алгоритма для нескольких наборов данных, я считаю, что в некоторых случаях он создает что-то вроде круглых форм и -подобных островков, где эти случаи похожи.
Однако я не видел этого эффекта в живой демонстрации от команды Google Brain: как эффективно использовать t-SNE. Возможно, из-за характера входных данных, 2 переменных в качестве входных данных.
Швейцарский рулон данных
t-SNE в соответствии с часто задаваемыми вопросами не очень хорошо работает с швейцарским рулоном . Тем не менее, это потрясающий пример того, как трехмерная поверхность (или коллектор ) с бетонной спиральной формой разворачивается как бумага благодаря технике уменьшения размеров.
Изображение взято из этой бумаги, где они использовали технику ваяния многообразия.
Теперь практика в R!
t-SNE помогает сделать кластер более точным, поскольку он преобразует данные в двумерное пространство, где точки имеют круглую форму (что приятно для k-средних и является одним из его слабых мест при создании сегментов).Подробнее об этом: кластеризация K-означает не бесплатный обед).
Сортировка данных Подготовка для применения моделей кластеризации.
библиотека (каретка) библиотека (Rtsne) ################################################## #################### ## ВЕСЬ пост находится в: https://github.com/pablo14/post_cluster_tsne ################################################## #################### ## Загрузите данные с: https://github.com/pablo14/post_cluster_tsne/blob/master/data_1.txt (URL-путь внутри гитрепо.) data_tsne = read.delim ("data_1.txt", header = T, stringsAsFactors = F, sep = "\ t") ## Функция RTSNE может занять несколько минут ... set.seed (9) tsne_model_1 = Rtsne (as.matrix (data_tsne), check_duplicates = FALSE, pca = TRUE, недоумение = 30, theta = 0.5, dims = 2) ## получение двумерной матрицы d_tsne_1 = as.data.frame (tsne_model_1 $ Y) Различные пробеги Rtsne приводят к разным результатам. Поэтому, скорее всего, вы не увидите точно такую же модель, как та, что представлена здесь.
Согласно официальной документации, недоумение связано с важностью соседей:
- «Это сравнимо с числом ближайших соседей k, которое используется многими учениками».
- "Типичные значения для диапазона недоумения от 5 до 50"
Объект tsne_model_1 $ Y содержит координаты X-Y ( V1 и V2 переменных) для каждого входного случая.
График результатов t-SNE:
## вывод результатов без кластеризации ggplot (d_tsne_1, aes (x = V1, y = V2)) + geom_point (размер = 0,25) + направляющие (color = guide_legend (override.aes = list (size = 6))) + xlab ("") + ylab ("") + ggtitle ("t-SNE") + theme_light (base_size = 20) + тема (axis.text.x = element_blank (), axis.text.y = element_blank ()) + scale_colour_brewer (palette = "Set2") 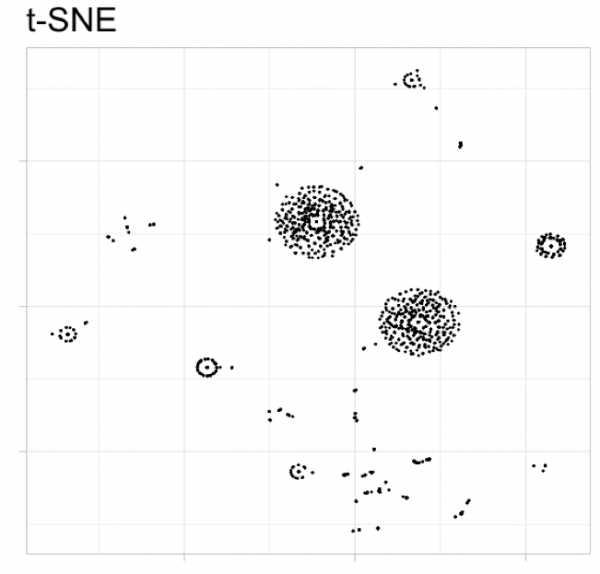
И есть знаменитые «острова» 🏝️. На данный момент, мы можем сделать некоторую кластеризацию, посмотрев на нее... Но давайте попробуем вместо этого k-среднее и иерархическую кластеризацию 😄. Страница часто задаваемых вопросов t-SNE предлагает уменьшить параметр недоумения, чтобы избежать этого, тем не менее, я не нашел проблемы с этим результатом.
Создание кластера моделей
Следующий фрагмент кода создаст k-средних и иерархических кластерных моделей . Затем назначить номер кластера (1, 2 или 3), которому принадлежит каждый входной регистр.
## с сохранением оригинальных данных d_tsne_1_original = d_tsne_1 ## Создание модели кластеризации k-средних и присвоение результата данным, использованным для создания tsne. fit_cluster_kmeans = kmeans (масштаб (d_tsne_1), 3) d_tsne_1_original $ cl_kmeans = factor (fit_cluster_kmeans $ cluster) ## Создание иерархической кластерной модели и присвоение результата данным, используемым для создания TSNE. fit_cluster_hierarchical = hclust (расстояние (шкала (d_tsne_1))) ## установка 3 кластеров в качестве вывода d_tsne_1_original $ cl_hierarchical = factor (cutree (fit_cluster_hierarchical, k = 3)) Размещение моделей кластера на выходе t-SNE
Теперь пришло время построить результаты каждой кластерной модели на основе карты t-SNE.
plot_cluster = function (data, var_cluster, palette) { ggplot (data, aes_string (x = "V1", y = "V2", color = var_cluster)) + geom_point (размер = 0,25) + направляющие (color = guide_legend (override.aes = list (size = 6))) + xlab ("") + ylab ("") + ggtitle ("") + theme_light (base_size = 20) + тема (axis.text.x = element_blank (), axis.text.y = element_blank (), legend.direction = "горизонтальный", legend.position = "bottom", legend.box = "горизонтальный") + scale_colour_brewer (palette = palette) } plot_k = plot_cluster (d_tsne_1_original, "cl_kmeans", "Accent") plot_h = plot_cluster (d_tsne_1_original, "cl_hierarchical", "Set1") ## и наконец: размещение графиков рядом с gridExtra lib... библиотека (gridExtra) grid.arrange (plot_k, plot_h, ncol = 2) 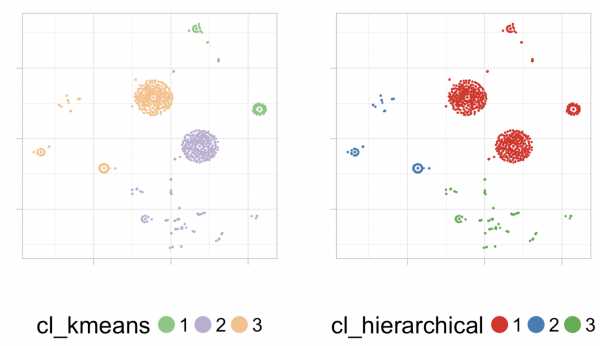
Визуальный анализ
В этом случае, и, основываясь только на визуальном анализе, кажется, что иерархический имеет больше здравого смысла, чем , чем k-среднее. Посмотрите на следующее изображение:
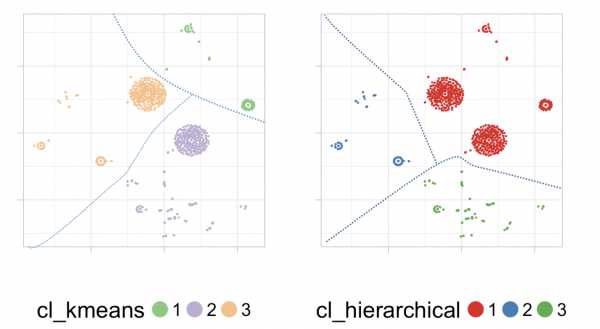
Примечание: пунктирные линии, разделяющие кластеры, были нарисованы от руки
В k-средних расстояние в точках в левом нижнем углу довольно близко по сравнению с расстоянием в других точках внутри того же кластера.Но они принадлежат к разным кластерам. Иллюстрирую это:
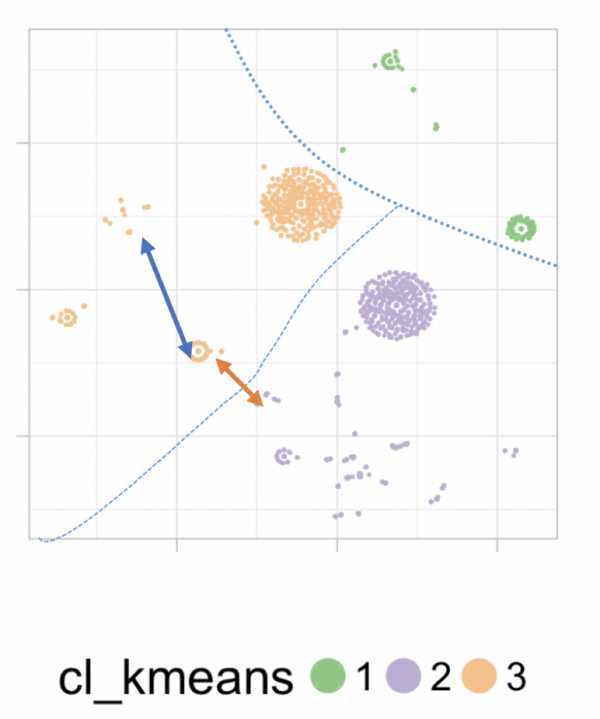
Итак, мы получили: красная стрелка короче синей стрелки ...
Примечание. Различные прогоны могут привести к разным группировкам. Если вы не видите этого эффекта в этой части карты, найдите его в другой.
Этот эффект не происходит в иерархической кластеризации. Кластеры с этой моделью кажутся более ровными. Но что вы думаете?
Смещение анализа (мошенничество)
Это несправедливо по отношению к k-означает, что так сравнивать.Последний анализ основан на идее плотности кластеризации . Эта техника действительно крутая, чтобы преодолеть недостатки простых методов.
Алгоритм HDBSCAN основывает свой процесс на плотностях.
Найдите суть каждого, посмотрев на эту картинку:
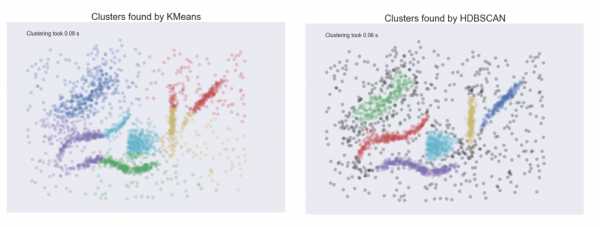
Конечно, вы поняли разницу между ними ...
Последнее изображение взято из сравнения алгоритмов кластеризации Python. Да, Python, но то же самое для R. Пакет большой Vis. (Примечание. Установите его, выполнив: install_github ("elbamos / largeVis", ref = "release / 0.2") .
глубокое обучение и т-SNE
Цитата Люка Меца из великого поста (Визуализация с помощью t-SNE):
В последнее время было много ажиотажа вокруг термина «глубокое обучение». В большинстве приложений эти «глубокие» модели можно свести к композиции простых функций, которые внедряются из одного многомерного пространства в другое. На первый взгляд, эти пространства могут казаться большими для размышления или визуализации, но такие методы, как t-SNE, позволяют нам начать понимать, что происходит внутри черного ящика.Теперь, вместо того, чтобы рассматривать эти модели как черные ящики, мы можем начать визуализировать и понимать их.
Глубокий комментарий 👏.
Окончательные варианты 🚀
Помимо этого поста, t-SNE оказался действительно отличным инструментом общего назначения для уменьшения размерности. Его можно использовать для изучения взаимосвязей внутри данных путем построения кластеров или для анализа случаев аномалий путем проверки изолированных точек на карте.
Игра с измерениями является ключевым понятием в науке о данных и машинном обучении.Параметр растерянности действительно похож на k в алгоритме ближайших соседей (k-NN). Отображение данных в 2-мерное, а затем сделать кластеризацию? Хм, не новый друг: самоорганизующиеся карты для сегментации клиентов.
Когда мы выбираем лучшие функции для построения модели, мы уменьшаем размерность данных. Когда мы строим модель, мы создаем функцию, которая описывает отношения в данных ... и так далее ...
Знаете ли вы общие понятия о k-NN и PCA? Ну, это еще один шаг, просто подключите кабели в мозг и все.Изучение общих понятий дает нам возможность установить связь между всеми этими методами. Несмотря на сравнение языков программирования, мощь, на мой взгляд, заключается в том, чтобы сосредоточиться на том, как ведут себя данные, и как эти методы в конечном итоге могут быть связаны.
Исследуйте воображение с этим видео Карла Сагана : Флатланд и 4-е измерение. Повесть о взаимодействии трехмерных объектов в двухмерной плоскости ...
Data Science Live Book (с открытым исходным кодом)
📌 Продолжите изучать науку о данных машинного обучения с Data Science Live Book (https: // livebook.datascienceheroes.com). Полностью доступны онлайн!

Страница загрузки книги 📥📘





